The Issue
My first foray into Ceph was at the end of last year. We had a small 72TB cluster that was split across 2 OSD nodes. I was tasked to upgrade the Ceph release running on the cluster from Jewel to Luminous, so that we could try out the new Bluestore storage backend, and add two more OSD nodes to the cluster which brought us up to a humble 183TB.
After the upgrade was complete, I noticed the Ceph dashboard and Ceph -s command state the following warning:
| |
At first I figured that it was probably due to a default setting in the Ceph configuration which was not changed relative to the growth that was expected for our cluster when it was initially set up. When I had a look at the /etc/ceph/ceph.conf file, I noticed two configurations:
| |
This corresponded with what I was seeing on the dashboard (or ceph -s):
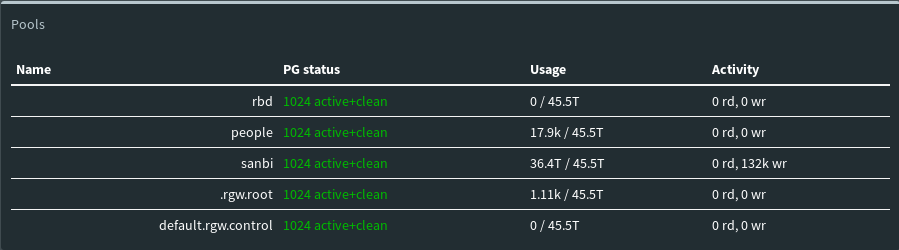
As you can see here, each of the pools that we have are assinged 1024 placement groups.
According to the Ceph documentation, you can use the calculation PGs = (number_of_osds * 100) / replica count to calculate the number of placement groups for a pool and round that to the nearest power of 2. For our environment, we have 44 osds and 2 replicas, so (44 * 100) / 2 = 2200. Rounding that up gives us 4096.
So according to that calculation we should have 4096 placement groups per pool! That means that I should be way under the max with my 1024 per pool. But if that’s the case, why is Ceph complaining?
The Solution
On Luminous, using the command ceph osd df tree will yield the following:
| |
As you can see from the above, each of the OSDs have a varying amount of placement groups (PGs) assigned to them. This configuration was fine for previous releases of Ceph (even though they actually recommend you don’t have more than 100 PGs per OSD), but it was reduced to 200 per OSD in Luminous. This is what is causing the error. To alleviate this, you can simply add the following two lines:
| |
to the [general] section of your ceph configuration file and push that to all the appropriate machines, then restart all the mgr and mon daemons in the cluster.
The Explanation
Resources
While the above should get rid of the warning, it’s good to understand why it is actually not recommended to run more than 100 PGs per OSD. The Ceph documentation on this does an ok job of explaining and I will try to expand on this. From their example:
For instance, a cluster of 10 pools each with 512 placement groups on ten OSDs is a total of 5,120 placement groups spread over ten OSDs, that is 512 placement groups per OSD. That does not use too many resources. However, if 1,000 pools were created with 512 placement groups each, the OSDs will handle ~50,000 placement groups each and it would require significantly more resources and time for peering.
The above example is saying that you have:
- 10 pools
- 10 OSDs
- 512 PGs per pool
10 pools x 512 PGs = 5120 PGs spread over 10 OSDs, which is 512 per OSD. This is already over the recommended PGs per OSD. Once you start adding more pools, you quickly encounter issues with scaling. 1000 pools now require there to be 512000 PGs which is 51200 per OSD. This leads to significant increase in memory and CPU usage across the cluster as finding data becomes a more complex process. It also means that latency goes down.
According to the Ceph documentation, 100 PGs per OSD is the optimal amount to aim for. With this in mind, we can use the following calculation to work out how many PGs we actually have per OSD: (num_of_pools * PGs_per_pool) / num_of_OSDs. Using my configuration of 1024 per pool, we see that (5 * 1024) / 44 = ~117. This means that I’m supposed to have around 117 PGs per OSD. This is where Ceph can be a little misleading.
PGs and Replication
When creating pools, Ceph takes the replication information in mind. If you have 2 replications and you create a new pool with 1024 PGs, Ceph needs to ensure that the data is always available via one replication, so it doubles up the pool. This means that creating a pool with 1024 PGs actually creates a pool of 2048 PGs in my case. Plugging that into the equation, (5 * 2048) / 44 = ~232, which is EXACTLY the complaint that Ceph has for me:
| |
This lovely little script by Laurent Barbe will show you a summary of the total PGs per pool AND per OSD. With it we can confirm that we actually have 2048 PGs per pool by running it and getting the following result:
| |
The only way to fix too many PGs for a pool would be to create a new pool, move the data from the old to the new and then delete the old.
I hope this clears things up for anyone struggling with Ceph PGs :)