
I was recently invited to give a workshop on reproducible scientific workflows to students as part of the Inter-university Institute for Data Intensive Astronomy’s (IDIA) “JEDI” programme. The overall purpose of this workshop was to introduce students from the African continent to various topics that are being dealt with in the data science space. A large focus here was machine learning.
This post details some of my experiences with preparing the original pipeline, working CWL around it and also teaching people how to do it.
Background
My boss originally informed me about the event and suggested that I get involved to give students a workshop on something slightly higher level than domain specific science. Due to the growing concept of research cloud computing and my involvement in the South African Data Intensive Research Cloud (SADIRC) joint project, we settled on the idea of giving students a crash course in infrastructure-as-code.
We were met with some hesitation after pitching the idea to some of the organisers. Non-CS domain scientists often don’t understand the usefulness of knowing some higher-level stuff about the environments that they run their code on… though, to be fair, a lot of CS scientists are bad too 😑.
Eventually I thought about reproducible scientific processes. I had been involved in turning bioinformatics pipelines into reproducible workflows in a hackathon held by the H3Africa, where I was exposed to the Common Workflow Language (CWL).
They agreed to have me give a workshop on using CWL to create reproducible data processing workflows, using an existing astronomy calibration and imaging pipeline created by Prof. Russ Taylor.
The Original Pipeline
Whew, that was a mouthful. Prepare for more!
To preface, I am not an expert with CWL and had fairly little experience with using it up until this point. I merely have a passion for automated and reproducible scientific work and have some experience with other workflow frameworks.
I received copies of the code used for the original pipeline. This code was all written in Python and some parts of it took advantage of a toolkit for astronomy called the Common Astronomy Software Applications (CASA).
The original code was all written within Jupyter, which is a fantastic frontend and tool for distributing Python code. Theoretically this should all be normal and fine, until you have a look at what was actually being done here.
The pipeline is broken up into multiple steps, each of which does something onto/to the resulting work from the previous step. The first step, calibration, takes data from a telescope and calibrates it to a known good source. Metadata about the datasets that are available for processing, including the amount of observations in each dataset, are defined by a simple datasets.py file, which contains classes to define them. This is imported into every part of the pipeline.
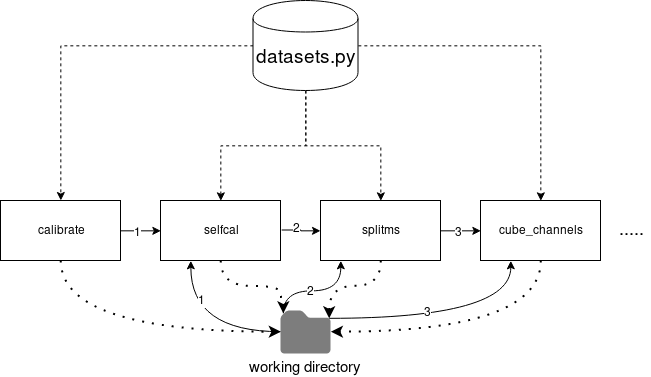
Each part of the pipeline has shared parameters that apply to the dataset and observations in question, as well as their own parameters which are unique to that step. This is repeated in every Jupyter notebook.
The pipeline also makes use of the slurm scheduler, where it is run against various virtual machines that act as an HPC environment on top of the IDIA cloud (don’t get me started…). The scripts being written in Jupyter do not allow this integration directly. To remedy this, the Jupyter notebooks effectively generate a large string of Python code syntax and tune it with the settings specified in the parameters set at the top of the given notebook. This string is written out as a plain .py file to the disk. A definition file for the scheduler is also written out and is run using the os.system() function from within the notebook, which then runs this script in a CASA Singularity container.
This is an interesting solution to say the least! The major advantage here is that you can prepare the dataset/observation and horizontally scale that out with additional slurm jobs.
Preparing for CWL-ification
CWL expects work units to fit into its idea of a “tool”. Basically, a tool is a script or binary which takes in some pre-defined input(s) and outputs some expected result(s). This does not necessarily have to be in terms of the results of the analysis you’re processing, but rather the files or text that you are expecting as output from this process.
This was the first challenge. None of the existing notebooks could be directly used as a tool for CWL and they were also doing too many things to be considered a coherent “tool” that focussed on doing one thing.
Each of the pipeline steps needed to be reworked. With maybe more than a month before the actual workshop, I had to focus on getting things working rather than making them pretty. I ended up splitting the preparation step out into its own tool, which would output a JSON file that would be used by the actual pipeline step. This was converted from this Python-code-as-a-string-to-be-written-out-to-a-script form into a separate Python script that used functions and parameters to apply parameter changes.
Wrapping in CWL
I converted each step of the pipeline into two tools: the preprocessing tool and the algorithm execution tool. Except for the very first step, calibration preparation, each tool would take the output of some previous one. The preparation tool does some preprocessing of the data and creates a data structure that would be read in by the actual work step which follows it.
With this pipeline using code from Prof. Taylor that he didn’t want exposed to the internet at the stage of the workshop, I was unable to create portable Docker/Singularity images to use as the tools. CWL works very well with Docker/Singularity and it’s definitely my preferred way of running workflows.
The two parts detailed below are strung together into what CWL refers to as a workflow, which is a separate file that defines which tools run at which steps of the pipeline as well as which tools depend on which outputs from others.
Preparation Part
Since I could not put the code on a public online location such as Dockerhub or Singularityhub, I opted to include the code to be run inside of the distribution of the workflow. The preparation steps for each part of the pipeline are plain Python3 scripts, so in order to move these scripts from the workflow directory to the CWL working directory (a temporary directory that is created with the tools/scripts/dependencies that the tool requires for the step that includes the tool) I treated the system python3 binary as the tool and provided the preparation script as a default input at first position in the final command-line mapping1.
The below snippet is the CWL definition for the preparation part of the calibrate step of the pipeline:
| |
calibration_prep.cwl
Algorithm Part
The crowd at IDIA keep custom CASA and WSClean (among other) Singularity containers that work at different parts of different researchers pipelines. This pipeline made use of some of those two mentioned. These custom built Singularity images were not worth uploading to Singularityhub for the purposes of running the workflow in the workshop, since they are quite large and not optimised for distribution. I opted to move the containers to the machine that the students would be executing the jobs on before hand and have them point to those during execution.
The below snippet is the CWL definition for the algorithmic part of the calibrate step of the pipeline:
| |
calibration.cwl
In this case I used the Singularity runtime as the tool and provided the script that calls functions from the CASA container (calibrate.py) as an input for that. This CWL tool also expects another input, calibration_input.dat, which is the output from the preparation step of this part of the pipeline.
The rest of the steps in the pipeline follow a very similar structure to the two mentioned above here.
Overview
The overview of the structure of the CWL workflow is as follows:
| |
Each of the pipeline steps are separated into a respective directory and all of the CWL tool definitions from each of the directories are strung together in the pipeline.cwl file, which is the overall workflow definition. The configuration.yml and configuration_jupyter.yaml files are essentially the same data files that provide the parameters for the pipeline execution, but they are just set differently with the one being set by manually editing it and the other being set through a Jupyter interface. Only one of them is specified when executing the workflow.
1: CWL maps the input arguments to the command-line with the appropriate positions as specified in the CWL definition. Using the above snippet (calibration_prep.cwl) as an example, it would look something like this:
python3 prepare.py configuration.yml ↩
The Workshop
Now that we have the background out of the way, let’s move on to the actual workshop and the process of getting the students to write CWL.
To prepare, I emptied the majority of the body of the workflow file that I was using for this pipeline, pipeline.cwl. I left the headings for some of the sections, since the students would be very unfamiliar with the structure of the CWL. I threw them into the deep end with the tool definitions by asking them to write tools for each part of the pipeline up to the splitms section, which was the last one I was able to complete before the workshop started. They had the existing code for the preparation and algorithm parts of each step in the pipeline to work with.
It was really interesting to watch them work. They had to take time to run the code and explore it individually to understand what each part was doing in order for them to start thinking about it in the sense of a workflow.
Tools
This was the first step for the students in the CWL work and it did introduce some confusion about why it is necessary to use CWL in the first place. I spent some time explaining the concepts and what this workflow language tries to achieve. When someone is completely unfamiliar with a concept and fails to understand its usefulness from an explanation, the only way to get them to understand is to have them work with it directly!
It didn’t take long for them to start understanding how CWL structures tool definitions. They wrapped all of the various steps in CWL fairly quickly, which serves to show the simplicity of CWL’s syntax and flow, as these students were not from a CS background. This was very encouraging to see.
Workflow
Creating the workflow itself was more challenging for them. They struggled a bit with logically following the flow of the analysis in terms of which tool outputs what and where that output needs to be fed to. They spent some time brainstorming and we worked through drawing it all out with pen and paper. This approach really helped them fully understand the layout and it was then much easier for them to build and debug the workflow.
Scattering
The most complicated part of the workflow for them was the scatter method that CWL uses to split work into chunks. In short, the scatter method is a way of defining how an array of inputs to a tool (which could be output from another) is processed. As of now, there are three types of scatter:
- dotproduct
- nested_crossproduct
- flat_crossproduct
Dotproduct is the simplest and basically means that each item in each array that is being scattered over will be used in a self-contained step. For example, if you have two array inputs that correspond with each other on index:
- listOfNames = [name1, name2, name3]
- phoneNumbers = [number1, number2, number3]
Each of the names correspond with each of the phone number on the index value, so name1’s phone number is number1 and name2’s is number2. Using dotproduct will mean that the inputs to the tool will be each index pair. If the tool is to print the name with the number next to it it would come out as:
| |
To read more about scattering, check the Common Workflow Language Documentation.
Result
Eventually, with some trial and error on their part and explanations of the various stages and operations of CWL from me, the group managed to fully complete the workflow for the challenge that was set out. They had built the workflow up to where I had and we could achieve the same results from running my original workflow and running theirs.
We built a Jupyter notebook frontend that could configure the various parameters needed by the pipeline and execute the CWL workflow. It must be noted that the parameters used for the observational dataset I provided the students were intentionally set with speed of execution in mind and not scientific accuracy, due to fear of not having enough time to debug and rerun the workflow.
For the most part, while building the workflow, we had been using the cwl-runner reference binary to execute the workflows. This is a tool provided by the CWL group that serves as a template base common set of functionality for other groups to build on. After I was satisfied with the state of their workflow we moved on to using the cwltoil executor, which has support for features like batch schedulers and implicit parallelism. The students even put together a neat little chart that showcased the difference in performance they achieved when using cwltoil coupled with slurm:
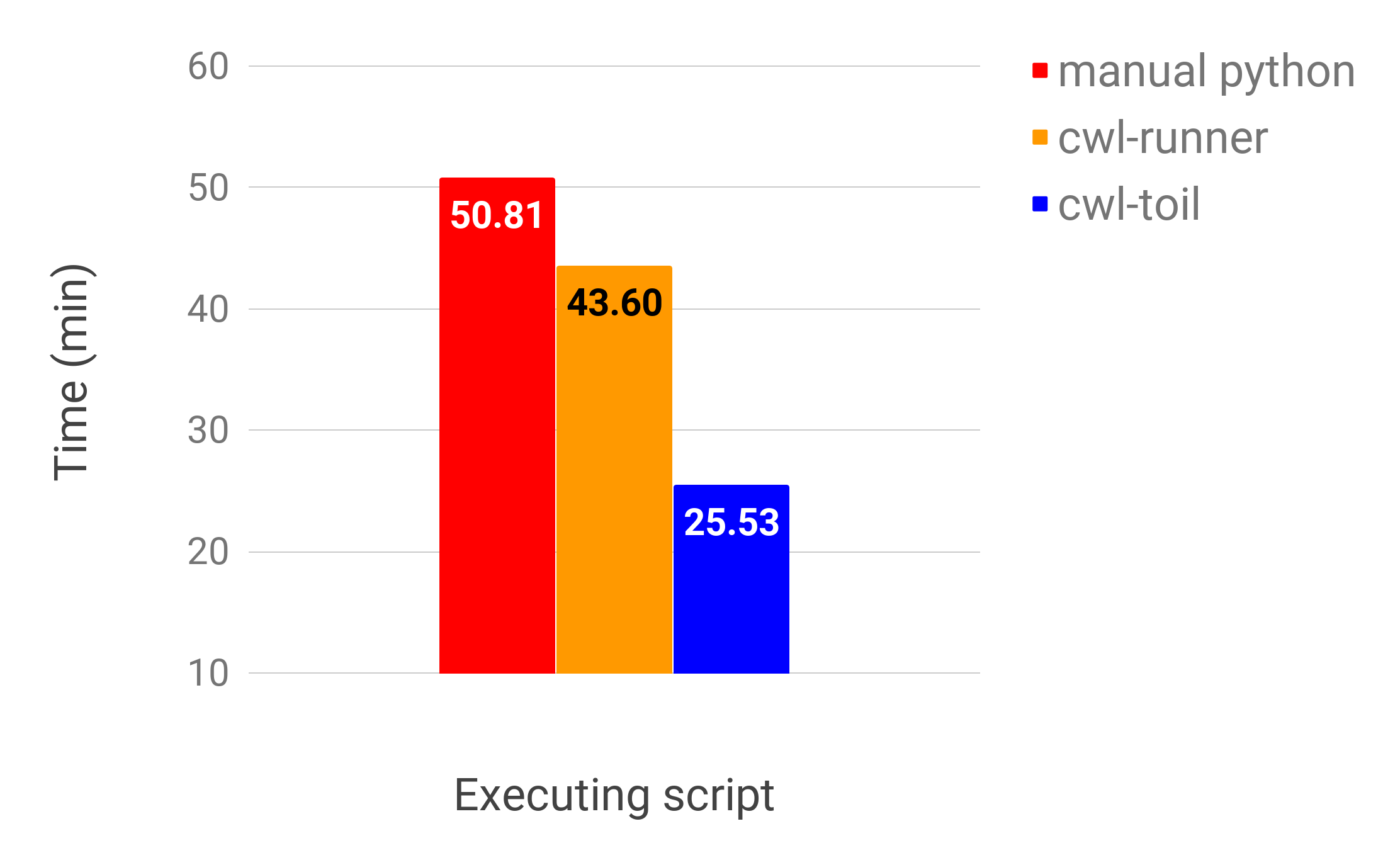
These results are to be expected. The results of the manual execution of each step and the cwl-runner step should be more or less the same, whereas the cwltoil execution should scale to be faster based on how many observations are enabled! In this case there were three.
Final Thoughts
Myself and the students had a blast while hacking away at the CWL workflow for this pipeline. They surely learnt a lot and I also picked up a few things that I hadn’t thought about before!
We weren’t able to make the workflow as portable as I would have liked. This is mainly due to not utilizing containers in the way that I had originally hoped to, but this wasn’t a train-smash and we discussed the theory of doing it this way.
There were some negative points that were brought to light with the exercise. The main things are:
CWL has bugs
This obviously goes for all software out there, but during the workshop we experienced some issues with executing the Singularity containers that I had brought with me. This was due to the way that cwl-runner was trying to execute these containers with specific versions of Singularity and it meant that the user required admin privileges, which goes against what we desire in this case. See this Github issue.
The developer community is incredibly responsive and eager to help. Once this issue was reported and a fix suggested it was merged and an update of the tool was released in around an hour or two!
No simple way to move files to working directory of tool
When we were originally working on the tools, we could not find a way to use a script that is shipped with the workflow as the baseCommand (or command/binary) from the same directory that the .cwl file is being called from. This stems from the way that CWL tries to encourage the usage of portable tools that are pre-packaged.
There may have been a solutions to this, but the ones we attempted would not work and we could not find much information about how to achieve this.
Paradigms
This probably ties into the above point, but along with this it took some time for the students to understand why this approach is better than what they had been doing up to now. Many researchers write large bash scripts that string together the tools that they want to use in their pipelines. Jupyter notebooks have aided in making it easier to move mainly Python based code, but CWL is a language and tool agnostic approach to this problem.
I suspect that this will be the case for many researchers to come.
Improving the workflow
There are ways that performance can be improved even further. Taking advantages of things such as subworkflows can allow steps in the workflow to not be held back by parts in the same step when using array inputs.
Containerization of the scripts and tools used could also ensure the portability of the workflow and I made sure to explain to the students why this is important to think about when they work with their own code.
Conclusion
Overall, I think that the workshop was a success and I know that the students learnt some skills that they will hopefully carry with them throughout their scientific careers.
I look forward to improving my own knowledge and skills with workflow standard and languages as well as teaching at more workshops in the future to spread the gospel! I’ll also probably eventually work up the desire to continue working on the workflow by rewriting the rushed code and finishing the rest of the steps in CWL.
It’s been a while since the workshop and I may have forgotten some of the points I wanted to raise in this blog post… also it’s probably not the most well-written post, but be gentle on me as I’m still getting into this blogging thing :)
Plus, Madagascar was beautiful! :D
