If you’re impatient, skip to the solution section 😃
Over the last few months I’ve been working with the University of Cape Town on the Ilifu research cloud project. The focus for the initial release of the cloud is mainly to provide compute and storage to astronomy and bioinformatics use cases.
The technology powering this cloud is the ever-growing-in-popularity combination of OpenStack (Queens release) as the virtualization platform and Ceph (Luminous) as the storage backend. We’re utilising the Kolla and Kolla-ansible projects to deploy the OpenStack side of things. I am the lead on the Ceph deployment and opted for the Ceph-ansible method of deployment.
We ran into some issues getting the OpenStack services to work on the Ceph cluster when using erasure coded pools…

Overview
To overview this to the reader, we intend to have a basic setup without an object store for the first user-testing focussed release of the cloud. We want the Ceph backend to provide RBD storage for the Cinder, Nova and Glance OpenStack services as well as CephFS to provide a shared filesystem environment through the Manila service.
Ceph provides two storage types:
- Replicated (default):
- The default type will duplicate the data for the amount of replications that the administrator specified in the
ceph.conf.
- The default type will duplicate the data for the amount of replications that the administrator specified in the
- Erasure coded:
- This is akin to RAID5. Data is broken up into chunks with parity chunks and stored on different devices to ensure that if some portion of the data is lost that it can be rebuilt. Depending on the erasure profile used, this can save space compared to replicated setups, but can also be more computationally expensive.
We want to put the OpenStack services on respective erasure coded pools on Ceph to save space and allow users to have the most possible storage available to them through the CephFS. That said, I went ahead and created 4 pools for the services:
images, controlled by the “glance” user;vms, controlled by the “nova” user;volumes, controlled by the “cinder” user; andvolumes-backup, controlled by the “cinder” user.
Each of the pools were set to use the erasure type, using a profile of k=3, m=1 with a failure domain of type rack. We have 4 racks of Ceph storage with a total of around 2PB of disk. The above erasure profile gives us the ability to lose 1 rack without losing any data, but one rack failure will lead to a loss in redundancy. This is a result of our relatively small cluster, which we can hopefully expand in the future.
The Issue
So all good right? I pushed the authentication keys and ceph.conf to the respective OpenStack service configuration directories and updated each service configuration files to reflect the location they need to look for for their slice of Ceph storage and let Kolla-ansible do its magic reconfiguring our cloud environment.
The deploy went smoothly and OpenStack comes up, I go to create an image and blam:
| |
None of the OpenStack services could talk to the Ceph storage correctly. After tons of Googling around and reconfiguring Ceph auth I figured out that the issue is actually caused by the erasure coding.
When an RBD image is created in a pool for OpenStack use, it requires the omap feature (allows you to store key/value data inside each object). Erasure coded pools lack this feature and as a result the interaction will fail. The two well known solutions to this is to either stick to using replicated pools, for which the feature is supported, or to use a caching tier on top of the erasure coding.
Solution
Not being satisfied by the above two solutions, I had a look around to see if there was any other way to get erasure coding to work more directly with the OpenStack services. I eventually stumbled across a seemingly undocumented feature in Ceph which you specify in the ceph.conf file called: rbd default data pool.
The Ceph client allows a data pool to be specified for an RBD image in order to offload writing data to the data pool while keeping metadata on the RBD pool. This is done using the command line argument --data-pool. For example:
| |
The above line will create an RBD image called myimage on the rbd pool. When data is written to the myimage, it will automagically be offloaded to the myimage_data pool, but all metadata will still be placed in the rbd pool.
Coming back to rbd default data pool, this configuration parameter basically sets a default --data-pool to each RBD command for whatever it’s applied to. So in the ceph.conf I ended up with the following:
| |
I also created a replicated pool and an erasure coded pool for each service:
| Metadata Pool | Data Pool |
|---|---|
| images | images_data |
| volumes | volumtes_data |
| volumes-backup | volumes-backup_data |
| vms | vms_data |
I made sure to enable ec_overwrites on the erasure coded pools (this is important!) and then restarted the Ceph daemons, copied the new ceph.conf to all of the OpenStack service directories, adjusted the RBD locations in the service configuration files and restarted the OpenStack services.
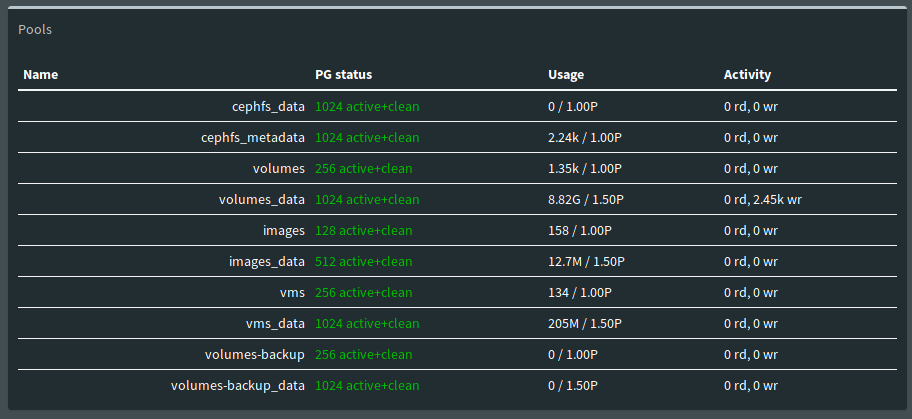
And Voila! I created a glance image and started up a virtual machine on OpenStack and all seemed to be working. As you can see in the following images, the metadata pools each have some small amount of data inside of them while the _data pools each have a larger amount of data inside of them:
I hope this helps! If I got anything wrong feel free to get in touch. I am was active on Twitter.