A little while ago I spent some time writing various Ansible roles and playbooks for the infrastructure at my place of work. My Ansible skills are intermediate and by no means refined. As a result of this, a lot of the roles were not developed to best practice specifications.
I took some time to try to improve my roles and properly test them before using them by taking advantages of the free continuous testing service that Travis-CI offers. I quickly ran into an issue while working on my role for deploying the Slurm scheduler, that being how do I test the deployment if I only have one VM to work on?
The answer? Docker and Docker-compose!
Slurm Scheduler
Slurm is a scheduling software. In brief, it manages a fleet of machines (which may have different hardware configurations) and decides which machines should execute jobs from which users in a multi-user cluster environment. This decision is based on various factors such as the sharing policy and the resources and/or time that the user is requesting from the cluster.
This is useful for environments where you have many users that need to run software that requires high amounts of system resources and takes long to run to completion, such as academic environments.
Slurm has 3 main services:
| Service | Description |
|---|---|
| slurmctld | This manages the fleet of hardware and the client service connects to this. |
| slurmdbd | This service connects to an existing DB and stores accounting information (think job histroy). |
| slurmd | This is the client service that runs on each of the machines that will execute jobs. |
For a typical environment, the slurmctld and slurmd services won’t be running on the same machine. This is to ensure that the slurmctld does not get starved of resources.
Ansible Role
The Ansible role that I wrote for deploying Slurm at my workplace (found here) is capable of deploying all of the Slurm services on an Ubuntu based (for now) cluster. For the gist of it, you specify an inventory file that determines which machines will have the slurmctld, slurmdbd and slurmd services deployed on them. This is specified in the following manner:
| |
Where slurm_builder defines which machine needs to do the building of the actual slurm software and a true value for headnode determines which machine needs to have the slurmctld and slurmdbd software deployed on it.
It should be clear to see that to accurately test this role I would need to run it with at lest two machines, having one speak to the other.
Testing the Role
Setup
In order to test the role with Travis, I made sure to link my Github profile with Travis-CI. After that, the directory structure of the project needs to be modified.
Here is what the original project structure looks like without Travis-CI:
| |
Adding the Travis-CI stuff brings us to this:
| |
Travis-CI gives you a single virtual machine to run your tests on. It also gives you the ability to write a pretty simple YAML document to specify the kind of environment that should be deployed onto your virtual machine. We want to use the Docker environmnet for this as it will provide us with both the Docker runtime as well as the docker-compose script. Since I created a travis/ directory in the main repo, I want to use that to place all our testing related files. So the .travis.yml file will look something like this:
| |
This will allow you to place anything inside of the travis/ directory and execute it on the VM that Travis-CI provides for you.
Docker and Docker Compose
Since I know that Travis-CI will now operate out of the travis/ directory, I created a docker-compose.yml file in there and populated it with a bunch of stuff that allows the simulation two independent networked machines. To do this, a Docker network needs to be created in the bridged mode so that static IP addresses can be assigned. With this done, each of the machines or “services” you create in the same docker-compose.yml will need that same network attached to it.
Here’s the full docker-compose.yml with some added comments for your understanding.
| |
As shown above, I need to build the Docker images that I needed for actually deploying the Ansible role onto. I created a headnode/ and computenode/ directory in the travis/ directory and placed a Dockerfile file in each of them. Both of the images are based off of the systemd-ubuntu:18.04 by jrei on DockerHub since the Ansible script relies on working with systemd. Along with this, some customisations were needed. I generated a random ssh keypair and stored the private key in the headnode Dockerfile and the public key in the computenode’s authorized_hosts file in order to allow keyless sshing for the Ansible to do its thing. These two Docker images can now, when deployed, act as a 2-node cluster on which we can test the Ansible deployment.
With all that being done, when deploying to GitHub, Travis should automatically trigger a job and execute whatever is in the install section of the .travis.yml file. It will bring up the two containers and they should be able to network to one another. The next step is to actually deploy the Ansible and to do some testing. To do this, I added the following to the .travis.yml file:
| |
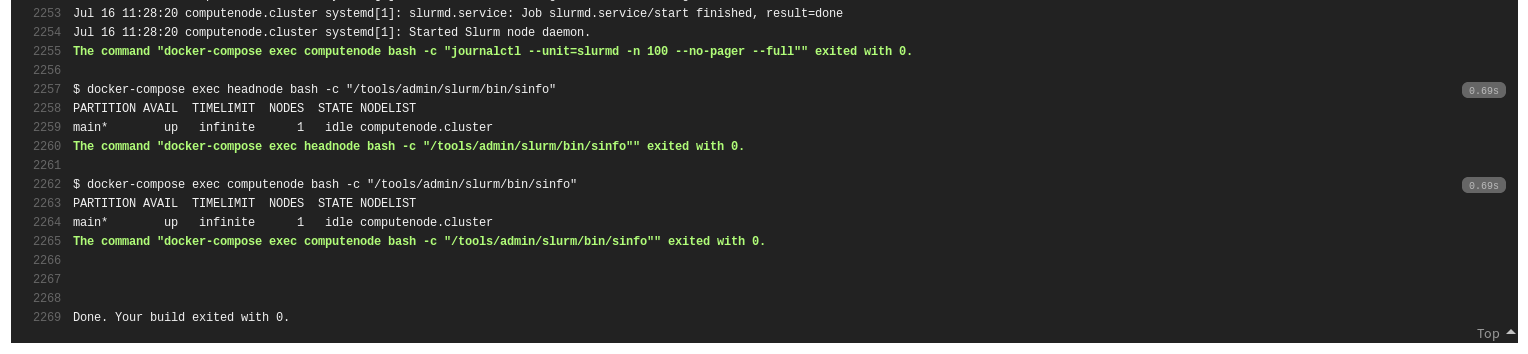
The steps under the script section will run syntax checks and do the deployment of the Ansible. Once that is complete, the contents of some files and directories will be outputted to stdout so that I may verify whether they are correct. I watch for the existence of some processes that I expect with ps and grep, check some logs for the services I’ve deployed and lastly I run some Slurm commands to confirm that all is working well.
The result works quite well!
Future Steps
My role refactoring is still a long way away and I’m sure that this is not the best way to test Ansible roles with Travis. I want to experiment with other testing systems such as Molecule. I also want to expand my roles to support different operating systems and make them more fault tolerant. I might also do some Travis matrix stuff in order to test all of the different operating system environments.
Maybe I’ll write another post about that when I get to it 😁